Neighborhood Relations of AEs and Clean Samples
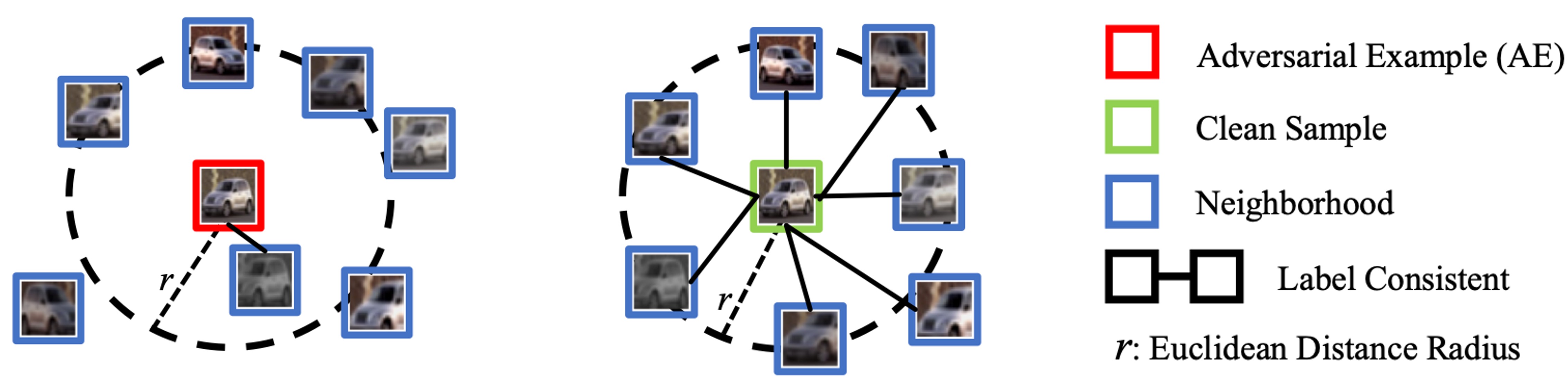
Figure 1. Neighborhood Relations of AEs and Clean Samples.
The previous method, Latent Neighbourhood Graph (LNG), represents the relationship between the input sample and the reference sample as a graph, whose nodes are embeddings extracted by DNN and edges are built according to distances between the input node and reference nodes, and train a graph neural network to detect AEs.
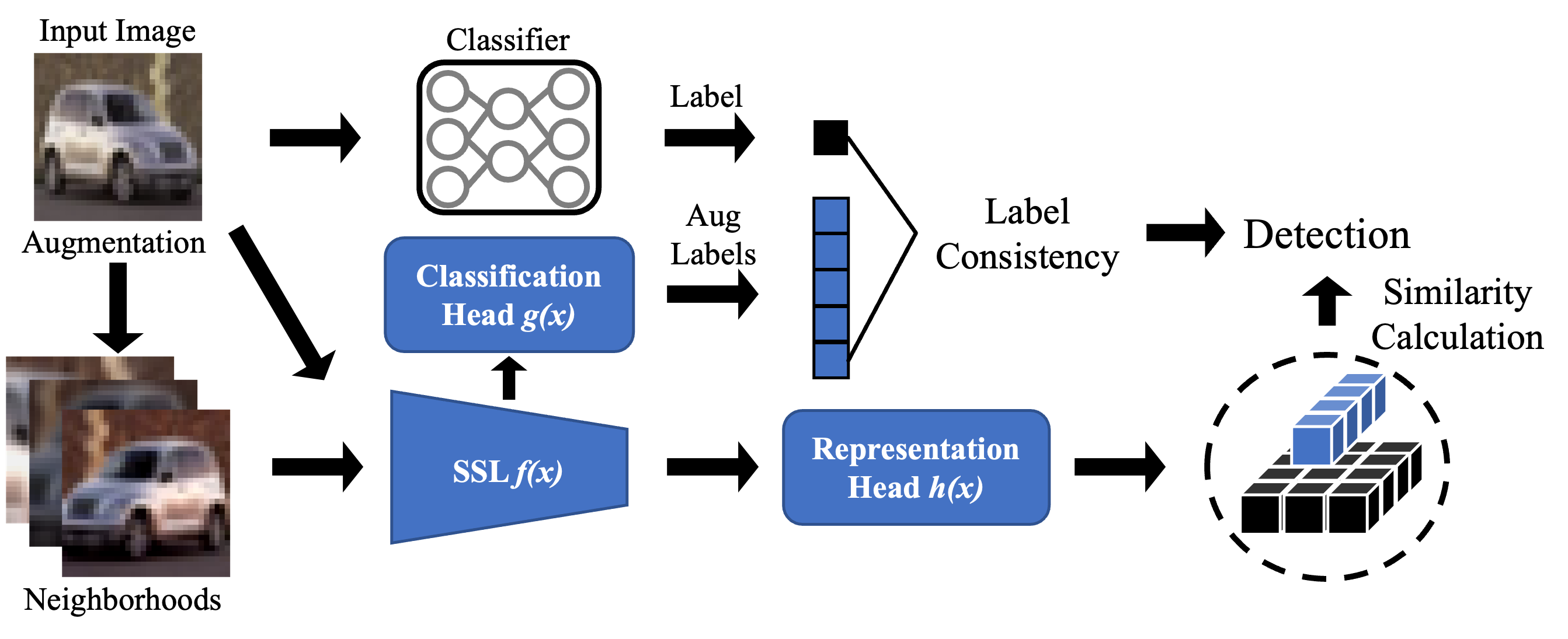
In this work, We explore the relationship between inputs and their test-time augmented neighbours. As shown in Figure. 1, clean samples exhibit a stronger correlation with their neighbors in terms of label consistency and representation similarity. In contrast, AEs are distinctly separated from their neighbors. According to this observation, we propose BEYOND to detection adversarial examples.